The Tech Behind Lens
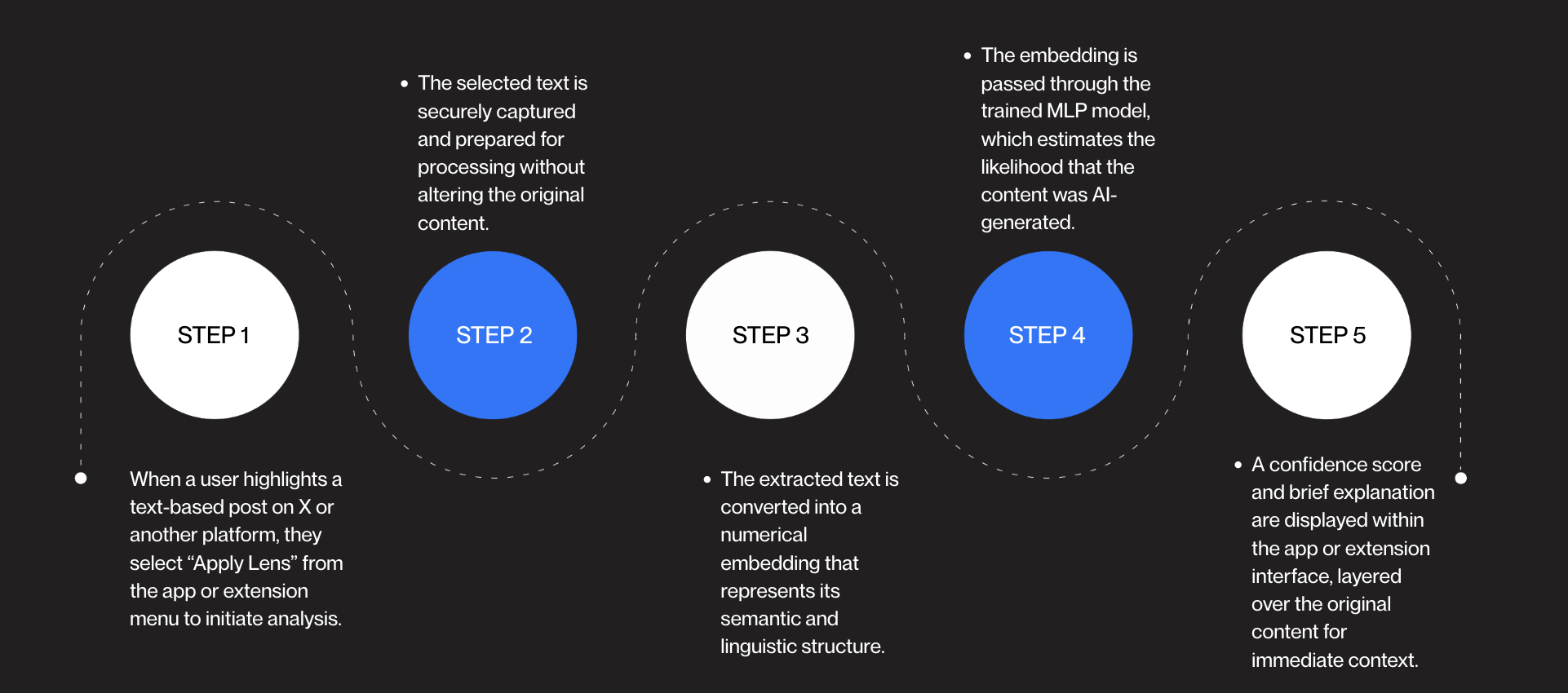
Tweets labeled as bot-generated or human-authored were split into training, validation, and testing datasets. To make the text data suitable for machine learning, OpenAI embeddings were generated to convert each tweet into a numerical vector representation. These vectors were organized into dataframes with factorized labels, where bot tweets were encoded as 0 and human tweets as 1. The features and labels were converted into NumPy arrays and used to train three classification models: K-Nearest Neighbors (KNN), Random Forest, and Multi-Layer Perceptron (MLP). Model performance was evaluated using accuracy, precision, recall, F1-score, and confusion matrices after hyperparameter tuning.